 |
|
Please Whitelist This Site?
I know everyone hates ads. But please understand that I am providing premium content for free that takes hundreds of hours of time to research and write. I don't want to go to a pay-only model like some sites, but when more and more people block ads, I end up working for free. And I have a family to support, just like you. :)
If you like The TCP/IP Guide, please consider the download version. It's priced very economically and you can read all of it in a convenient format without ads.
If you want to use this site for free, I'd be grateful if you could add the site to the whitelist for Adblock. To do so, just open the Adblock menu and select "Disable on tcpipguide.com". Or go to the Tools menu and select "Adblock Plus Preferences...". Then click "Add Filter..." at the bottom, and add this string: "@@||tcpipguide.com^$document". Then just click OK.
Thanks for your understanding!
Sincerely, Charles Kozierok
Author and Publisher, The TCP/IP Guide
|
|

|

Custom Search
|

|





HTTP Caching Features and Issues
(Page 1 of 3)
The explosive growth of the World Wide Web was a marvel for its users, but a nightmare for networking engineers. The biggest problem that the burgeoning Web created was an overloading of the internetworks over which it ran. Many of the features that were added to HTTP/1.1 were designed specifically to improve the efficiency of the protocol and reduce unnecessary bandwidth consumed by HTTP requests and responses. Arguably the most important of these is a set of features designed to support caching.
The subject of caching comes up again and again in discussions of computers and networking, because of a phenomenon that is widely observed in these technologies: whenever a user, hardware device or software process requests a particular piece of data, there is a good chance it will ask for it again in the near future. Thus, by storing recently-retrieved items in a cache, we can eliminate duplicated effort. This is why caching plays an important role in the efficiency of protocols such as ARP and DNS.
Caching is important to HTTP because Web users tend to request the same documents over and over again. For example, in writing this section on HTTP, I made reference to RFC 2616 many, many times. Each time, I loaded it from a particular Web server. Since the document never changes, it would be more efficient to just load it from a local cache rather than having to retrieve it from the distant Web server each time.
However, caching is even more essential to HTTP than to most other protocols or technologies where it used. The reason is that Web documents tend to be structured so that a request for one resource leads to a request for many others. Even if I load a number of different documents, they may each refer to common elements that do not change between user requests. Thus, caching can be of benefit in HTTP even if a user never asks for the same document twice, or if a single document changes over time so that caching the document itself would be of little value.
For example, suppose that each morning I load up CNN’s Web site to see what is going on in the world. Obviously, the headlines will be different every day, so caching of the main CCN.com Web home page won’t be of much value. However, many of the graphical elements on the page (CNN’s logo, dividing bars, perhaps a “breaking news” graphic) will be the same, every day, and these can be cached. Another example would be a set of discussion forums on a Web site. As I load up different topics to read, each one is different, but they have common elements (such as icons and other images) that would be wasteful to have to retrieve over and over again.
Caching in HTTP yields two main benefits. The first is reduced bandwidth use, by eliminating unneeded transfers of requests and responses. The second, equally important, is faster response time for the user loading a resource. Consider that on many Web pages today, the image files are much larger than the HTML page that references them. Caching these graphics will allow the entire page to load far more quickly. Figure 319 illustrates how caching reduces bandwidth and speeds up resource retrieval by “short-circuiting” the request/response chain.
|
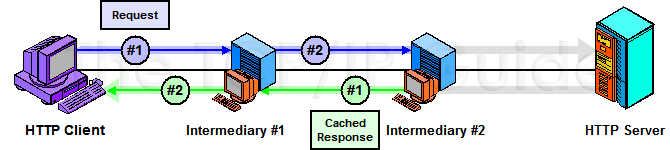
The obvious advantages of caching have made it a part of the Web since pretty much the beginning. However, it was not until HTTP/1.1 that the importance of caching was really recognized in the protocol itself, and many features added to support it. Where the HTTP/1.0 standard makes passing mention of caching and some of the issues related to it, HTTP/1.1 devotes 26 full pages to caching (over 20% of the main body of the document!) I obviously cannot go into that level of detail here, but I will discuss HTTP caching in general terms to give you a feel for the subject.
|
| |||||||||||||||||||
Home - Table Of Contents - Contact Us
The TCP/IP Guide (http://www.TCPIPGuide.com)
Version 3.0 - Version Date: September 20, 2005
© Copyright 2001-2005 Charles M. Kozierok. All Rights Reserved.
Not responsible for any loss resulting from the use of this site.